Classification Method
The main idea of this classification is to distinguish different vegetation classes using a common classification method applied to the spectral imagery of a study area. The classification is based on the differences in reflection of the specific surfaces in the area in several electromagnetic wavelengths.
Classification using Spectral Imagery
The concept of using spectral imagery for classification purposes is based on the different spectral signatures of the recorded surface to define the different classes. For mapping vegetation, it is most common to use the spectral radiance in the visible light as well as in the NIR regions of the electromagnetic spectrum (Mather and Koch 2011).
We are using a supervised classification method. This means that we use a training set with already known classes, which are defined by the user. It is necessary that the user needs to know for some random areas to which of the vegetation classes they belong. After specifying this, the algorithm proceeds to assign these classes to the rest of the pixels based on the spectral signature. This way, a classifier is developed which can be used to assign the classes to newly added data, e.g. a new year or another area, as well (Černá and Chytry 2005). Therefore, the process does not need to be repeated for new data. However, reference data is required to define the training dataset used for the classification (Xie et al. 2008).
Random Forest Classification
This specific classification method is using the random forest algorithm . A random forest consists of many decision trees. A decision tree is used for representation of the decision rules the algorithm makes. Using one decision tree, the algorithm first decides in a hierarchical order which main classes the pixel belongs too, and then moves in a specific direction to decide on the specific class. Using vegetation as example, first the algorithm would decide if the pixel is vegetation at all, or something else such as water or bare soil. If it does decide that it is vegetation, the algorithm starts narrowing it down to a more specific vegetation class.
The random forest algorithm uses many decision trees which are independent from each other, see the image below for a visual representation of such a decision tree. They use different training datasets from the original dataset. Every tree decides for a class, dependent on the characteristics. The highest rate determines the final class.
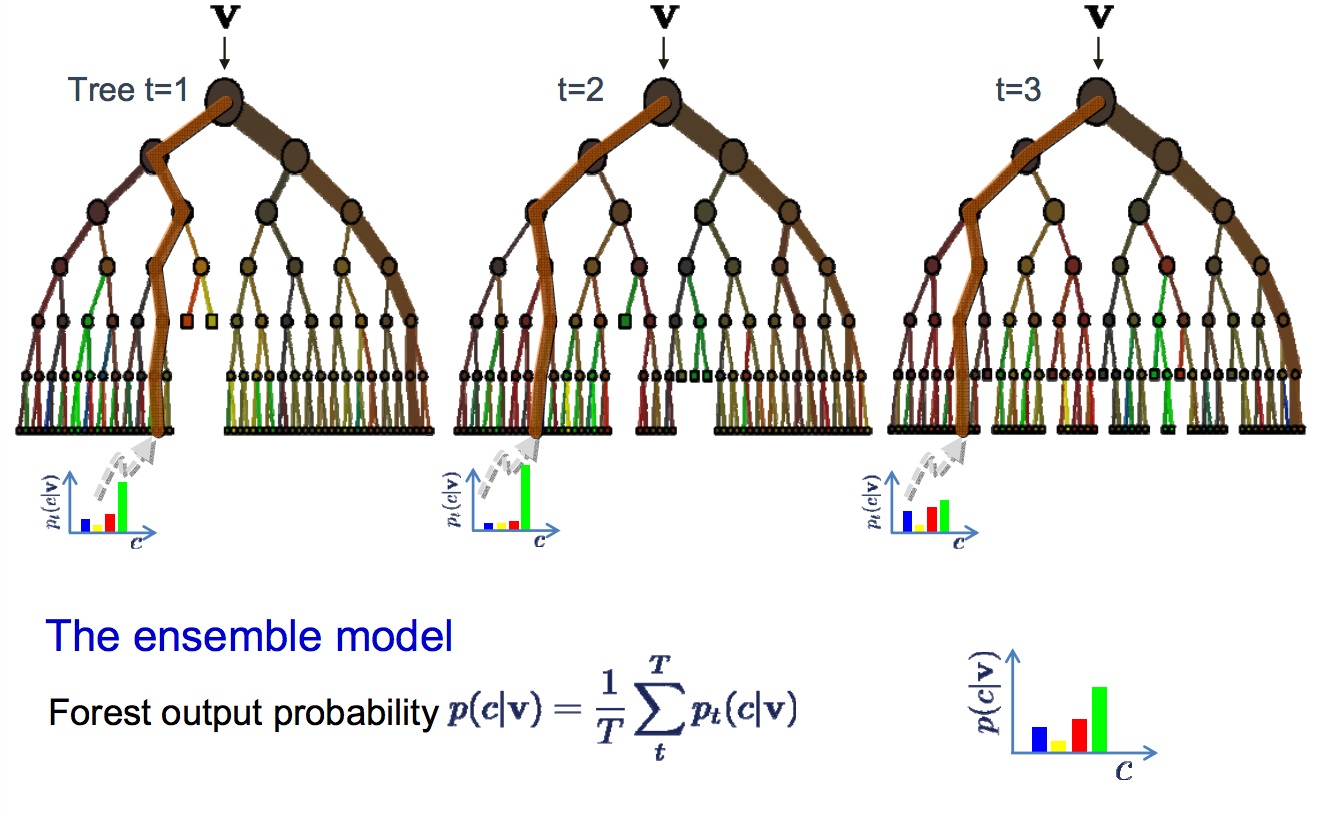
Decision trees in random forest
Advantages of the random forest method are that the classification is very fast; the training and building time is short. Also, the evaluation is fast because every tree is calculated separately. Huge amounts of data can thus be calculated efficiently, and interconnections and importance of classes can be detected (Breiman 2001). For a more in-depth explanation visit listen data, and to get the R documentation visit this page.
Breiman, Leo. 2001. “Random Forests.” Machine Learning 45 (1). Springer: 5–32.
Černá, and Chytry. 2005. “Supervised Classification of Plant Communities with Artificial Neural Networks.” Journal of Vegetation Science 16 (4). Wiley Online Library: 407–14.
Mather, Paul M, and Magaly Koch. 2011. “Hardware and Software Aspects of Digital Image Processing.” Computer Processing of Remotely-Sensed Images: An Introduction, Fourth Edition. Wiley Online Library, 67–85.
Xie et al. 2008. “Remote Sensing Imagery in Vegetation Mapping: A Review.” Journal of Plant Ecology 1 (1). Oxford University Press: 9–23.